Comparing Sentence Similarity Methods
By Yves Peirsman, 2 May 2018
Word embeddings have become widespread in Natural Language Processing. They allow us to easily compute the semantic similarity between two words, or to find the words most similar to a target word. However, often we're more interested in the similarity between two sentences or short texts. In this blog post, we'll compare the most popular ways of computing sentence similarity and investigate how they perform. For people interested in the code, there's a companion Jupyter Notebook with all the details.
Many NLP applications need to compute the similarity in meaning between two short texts. Search engines, for example, need to model the relevance of a document to a query, beyond the overlap in words between the two. Similarly, question-and-answer sites such as Quora need to determine whether a question has already been asked before. This type of text similarity is often computed by first embedding the two short texts and then calculating the cosine similarity between them. Although word embeddings such as word2vec and GloVe have become standard approaches for finding the semantic similarity between two words, there is less agreement on how sentence embeddings should be computed. Below we’ll review some of the most common methods and compare their performance on two established benchmarks.
Data
We'll evaluate all methods on two widely used datasets with human similarity judgements:
- The STS Benchmark brings together the English data from the SemEval sentence similarity tasks between 2012 and 2017.
- The SICK data contains 10,000 English sentence pairs labelled with their semantic relatedness and entailment relation.
The table below contains a few examples from the STS data. As you can see, the semantic relationship
between the two sentences is often quite subtle: the sentences a man is playing a harp and a man is playing a keyboard are judged as very dissimilar,
although they have the same syntactic structure and the words in them
have very similar embeddings.

Similarity Methods
There is a wide range of methods for calculating the similarity in meaning between two sentences. Here we take a look at the most common ones.
Baselines
The easiest way of estimating the semantic similarity between a pair of sentences is by taking the average of the word embeddings of all words in the two sentences, and calculating the cosine between the resulting embeddings. Obviously, this simple baseline leaves considerable room for variation. We’ll investigate the effects of ignoring stopwords and computing an average weighted by tf-idf in particular.
Word Mover’s Distance

One interesting alternative to our baseline is Word Mover’s Distance. WMD uses the word embeddings of the words in two texts to measure the minimum distance that the words in one text need to “travel” in semantic space to reach the words in the other text.
Smooth Inverse Frequency
Taking the average of the word embeddings in a sentence tends to give too much weight to words that are quite irrelevant, semantically speaking. Smooth Inverse Frequency tries to solve this problem in two ways:
- Weighting: like our tf-idf baseline above, SIF takes the weighted average of the word embeddings in the sentence.
Every word embedding is
weighted by
a/(a + p(w)), whereais a parameter that is typically set to0.001andp(w)is the estimated frequency of the word in a reference corpus. - Common component removal: next, SIF computes the principal component of the resulting embeddings for a set of sentences. It then subtracts from these sentence embeddings their projections on their first principal component. This should remove variation related to frequency and syntax that is less relevant semantically.
As a result, SIF downgrades unimportant words such as but, just, etc., and
keeps the information that contributes most to the semantics of the sentence.
Pre-trained encoders
All methods above share two important characteristics. First, as simple bag-of-word methods,
they do take not word order into account. Second, the word embeddings they use have been learned
in an unsupervised manner. Both these traits are potentially harmful. Since differences in
word order often go hand in hand with differences in meaning (compare the dog bites the man with the man bites the dog),
we'd like our sentence embeddings to be sensitive to this variation. Additionally, supervised training
can help sentence embeddings learn the meaning of a sentence more directly.
This is where pre-trained encoders come in. Pre-trained sentence encoders aim to play the same role as word2vec and GloVe, but for sentence embeddings: the embeddings they produce can be used in a variety of applications, such as text classification, paraphrase detection, etc. Typically they have been trained on a range of supervised and unsupervised tasks, in order to capture as much universal semantic information as possible. Several such encoders are available. We'll take a look at InferSent and the Google Sentence Encoder.

InferSent is a pre-trained encoder that was developed by Facebook Research. It is a BiLSTM with max pooling, trained on the SNLI dataset, 570k English sentence pairs labelled with one of three categories: entailment, contradiction or neutral.
The Google Sentence Encoder is Google’s answer to Facebook’s InferSent. It comes in two forms:
- an advanced model that takes the element-wise sum of the context-aware word representations produced by the encoding subgraph of a Transformer model.
- a simpler Deep Averaging Network (DAN) where input embeddings for words and bigrams are averaged together and passed through a feed-forward deep neural network.
The Transformer-based model tends to give better results, but at the time of writing, only the DAN-based encoder was available. In contrast to InferSent, the Google Sentence Encoder was trained on a combination of unsupervised data (in a skip-thought-like task) and supervised data (the SNLI corpus).
Results
We tested all the methods above by getting their similarities for the sentence pairs in the development and test sets of the SICK and STS data, and computing their correlation with the human judgements. We’ll mostly work with Pearson correlation, as is standard in the literature, except where Spearman correlation gives different results.
Baselines
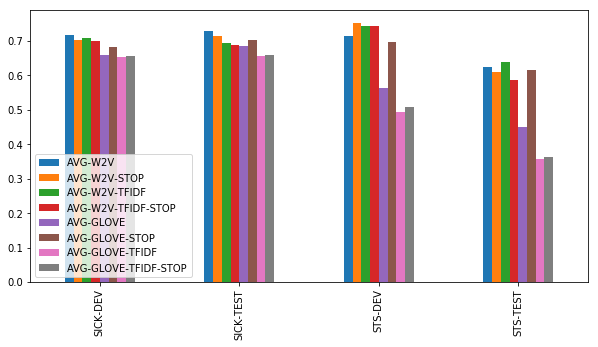
Despite their simplicity, the baseline methods that take the cosine between average word embeddings can perform surprisingly well. Still, a few conditions have to be met:
- Simple word2vec embeddings outperform GloVe embeddings.
- With word2vec, it is unclear whether using a stoplist or tf-idf weighting helps. On STS it sometimes does, on SICK it does not. Simply computing an unweighted average of all word2vec embeddings consistently does pretty well.
- With GloVe, using a stoplist is crucial to obtaining good results. Using tf-idf weights does not help, with or without a stoplist.
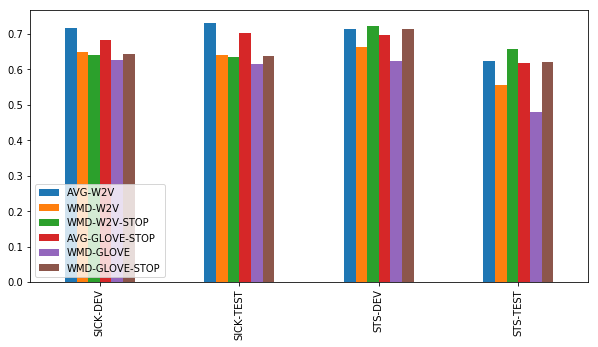
Word Mover’s Distance
Based on our results, there’s little reason to use Word Mover’s Distance rather than simple word2vec averages. Only on STS-TEST, and only in combination with a stoplist, can WMD compete with the simpler baselines.
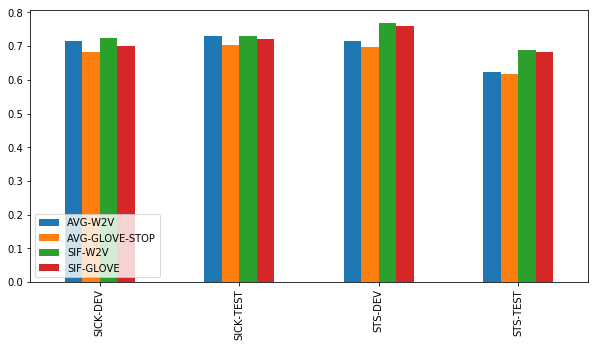
Smooth Inverse Frequency
Smooth Inverse Frequency is the most consistent performer in our tests. On the SICK data, it does about as well as its baseline competitors, on STS it outranks them by a clear margin. Note there is little difference between SIF with word2vec embeddings and SIF with GloVe embeddings. This is remarkable, given the large differences between the two we observed above. It shows SIF’s weighting and common component removal effectively reduces uninformative noise from the embeddings.
Pre-trained encoders
Pre-trained encoders have a lot to be said for them. However, our results indicate they are not yet able to capitalize fully on their training regime. Google’s Sentence Encoder looks like a better choice than InferSent, but the Pearson correlation coefficient shows very little difference with Smooth Inverse Frequency.
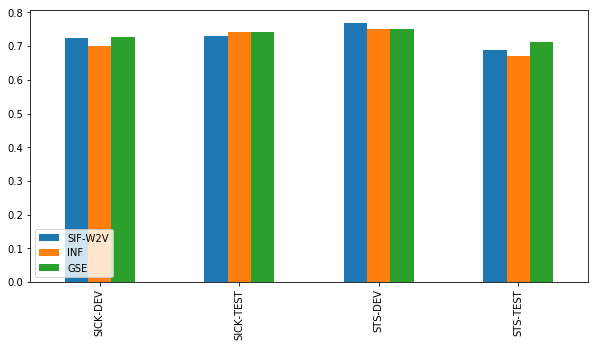
The differences in Spearman correlation are more outspoken. This may indicate that the Google Sentence Encoder more often gets the ordering of the sentences right, but not necessarily the relative differences between them.
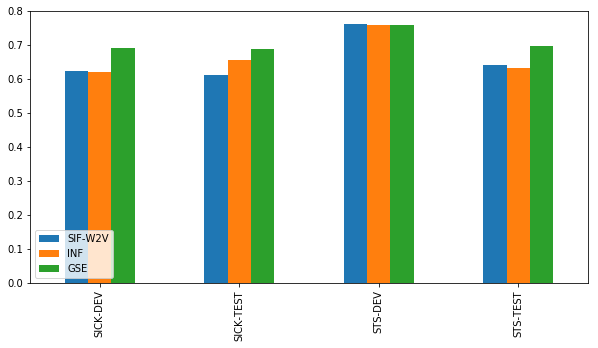
Conclusions
Sentence similarity is a complex phenomenon. The meaning of a sentence does not only depend on the words in it, but also on the way they are combined. As the harp-keyboard example above shows, semantic similarity can have several dimensions, and sentences may be similar in one but opposite in the other. Current sentence embedding methods only scratch the surface of what’s possible.
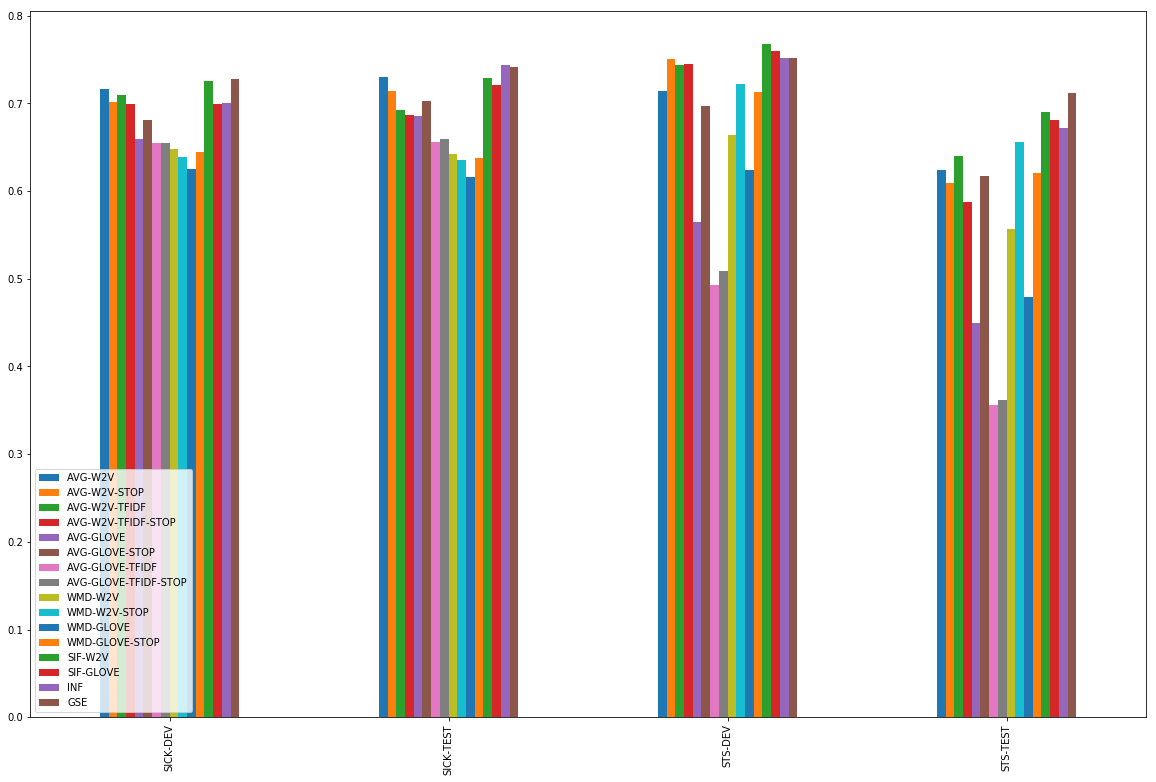
So, what should you do when you’re looking to compute sentence similarities? Our results suggest the following:
- Word2vec embeddings are a safer choice than GloVe embeddings.
- Although an unweighted average of the word embeddings in the sentence holds its own as a simple baseline, Smooth Inverse Frequency is usually a stronger alternative.
- If you can use a pre-trained encoder, pick Google's Sentence Encoder, but remember its performance gain may not be all that spectacular.

Yves Peirsman
Yves is the Natural Language Processing expert at NLP Town. He holds an MSc in Speech & Language Processing from the University of Edinburgh, and a PhD in Computational Linguistics from the University of Leuven. After spending some time as a post-doctoral researcher at Stanford University, he traded academia for industry. In 2014 he founded NLP Town to help companies and organizations implement NLP solutions successfully.