Adventures in Zero-Shot Text Classification
By Yves Peirsman, 25 May 2021
Transfer learning has had an enormous impact in Natural Language Processing. Thanks to models like BERT, it is now possible to train more accurate NLP models than before, and typically do so with less labeled data. Now that finetuning language models has become the standard procedure in NLP, it’s only natural to get curious and ask: do we need any task-specific labeled training items at all? In this article, we investigate two available models for zero-shot text classification and evaluate how they perform. The code for this article is available in our repository of NLP notebooks.
Zero-shot text classification
Zero-shot and few-shot NLP models take transfer learning to the extreme: their goal is to make predictions for an NLP task without having seen one single labeled item (for zero-shot learning), or very few such items (for few-shot learning) specific to that task. The most well-known example is doubtlessly OpenAI’s GPT-3, which has proved to be a very successful few-shot learner for a wide range of applications. While running GPT-3 lies beyond the means of most developers, luckily several smaller alternatives are available.
In 2020, Flair and Transformers, two of the most popular NLP libraries, both added zero-shot classification to their offering. Flair, on the one hand, makes use of a so-called TARS classifier, short for Text-Aware Representation of Sentences, which can be run with just a few lines of code:
classifier = TARSClassifier.load('tars-base')
sentence = Sentence('Your example text')
classifier.predict_zero_shot(sentence, [label1, label2, …])
Transformers, on the other hand, makes it possible to use a range of models from the Hugging Face model hub
in their zero-shot-classification pipeline:
classifier = pipeline('zero-shot-classification', model="your-nli-model", device=0)
classifier('Your example text', [label1, label2, …])
Despite the obvious similarities, the two implemented classifiers approach zero-shot text classification quite differently.
The zero-shot pipeline in the Transformers library treats text classification as natural language inference (NLI).
This approach was pioneered by Yin et al. in 2019.
In NLI, a model takes two sentences as input — a premise and a hypothesis — and decides whether the hypothesis
follows from the premise (entailment), contradicts it (contradiction), or neither (neutral). For example,
the premise David killed Goliath entails the hypothesis Goliath is dead, is contradicted by
Goliath is alive and doesn’t allow us to draw any conclusions about Goliath is a giant. This NLI
template can be reused for text classification by taking the text we’d like to label as the premise, and
rephrasing every candidate class as a hypothesis. For a task such as polarity classification, the
premise could be an opinion like I loved this movie, with the hypotheses This sentence is positive,
This sentence is negative or This sentence is neutral. The classifier will then determine the relationship
between the premise and every hypothesis.
In single-label classification, all resulting entailment scores
are softmaxed to identify the single most probable class; in multi-label classification, the scores for entailment and
contradiction are softmaxed for every label independently, so that several relevant labels can be identified.
The TARS classifier in the Flair library takes a different course. Similar to the previous approach,
it abstracts away from the specificities of individual classification tasks by feeding both the
label and the text as input to a BERT classifier, separated by the [SEP] token. The main difference
lies in the fact that this BERT model is not finetuned for NLI, but for a generic version of text
classification. This is done by training the model to label every input pair
as either true or false. To make sure
it can handle a variety of classification tasks, Flair’s TARS classifier is
finetuned on nine different datasets, with applications ranging from polarity to topic classification.
For single-label classification, only the class with the highest score for True is selected as the final prediction;
for multi-label classification, all classes with the prediction True are returned.
Although both approaches to zero-shot classification sound very attractive, they share one disadvantage: in contrast to traditional text classification, each input text requires several forward passes through the model — one for each candidate label. The models are therefore less computationally efficient than more traditional text classifiers. Still, if they can bypass the need for expensive data labeling, for many applications this may be a small price to pay.
Evaluation
The more pressing question is therefore how well zero-shot text classification works exactly. To find out, we evaluated the classifiers above on five different tasks, from topic classification to sentiment analysis. We used four datasets that are all available from the Hugging Face datasets hub, making sure that none of these datasets was used to finetune Flair’s TARS classifier. From each we selected 1,000 random test items:
- yahoo_answers_topics: questions and answers from Yahoo Answers, classified into 10 topics,
such as
Society & CultureandScience & Mathematics. As the input to the model we use the best answer only (without the question). - banking 77: a set of online user queries from the banking domain, each labeled
with one of 77 intents. This is a challenging dataset, as the intents (such as
card_about_to_expireandcard_not_working) are very fine-grained. - tweet_eval: English tweets labeled for a variety of tasks. We tested if the models
can predict the emotion —
anger,joy,optimismorsadness— and the sentiment polarity of the tweets —positive,negativeorneutral. - financial_phrasebank: financial news sentences (such as Sales have risen in other export markets) with a polarity
label —
positive,negativeorneutral. We only selected sentences for which all annotators agreed on the label.
We used three different zero-shot text classifiers in our tests: Flair’s TARSClassifier,
and two Transformers models finetuned for NLI: bart-large-mnli and roberta-large-mnli. The graph below shows
their accuracies on the five tasks. The results are as varied as the
datasets, but one pattern is immediately clear: the best model always takes the NLI approach.
For the Yahoo Answers topics, Bart gives the best accuracy (39.2%), followed by TARS and Roberta, which both obtain 27.5%.
Although the banking task appears much more challenging at first sight, the NLI models perform even better here: they
both classify over 41% of the test items correctly, leaving the TARS classifier far behind. On four-way tweet emotion classification,
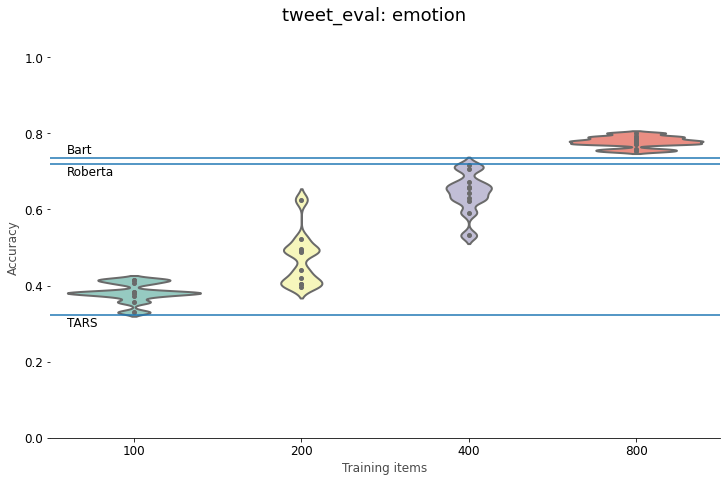
both Bart (73.6%) and Roberta (71.9%) perform surprisingly well and easily beat TARS (32.3%).
The two polarity tasks deserve some additional explanation. Because our first evaluation run showed very low
scores for TARS (accuracies below the random baseline of 33%), we took a closer look at the results and found
that in most cases, TARS failed to predict a single label for the news sentences and tweets. To fix this,
we performed a second run, where we made TARS return neutral for every sentence without a label.
It is those scores you see below.
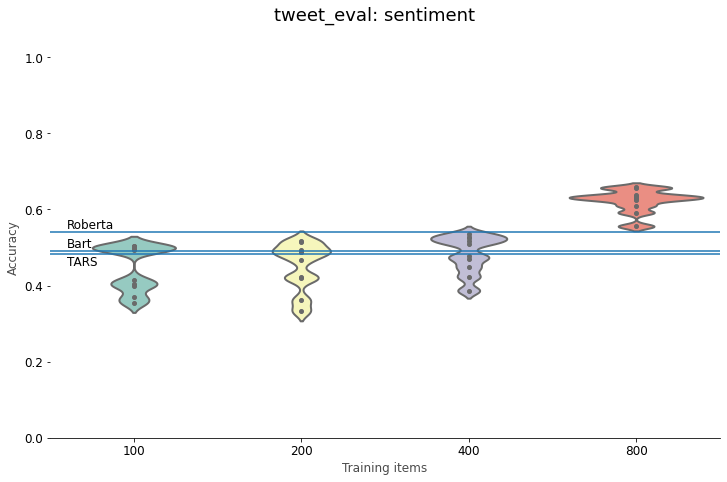
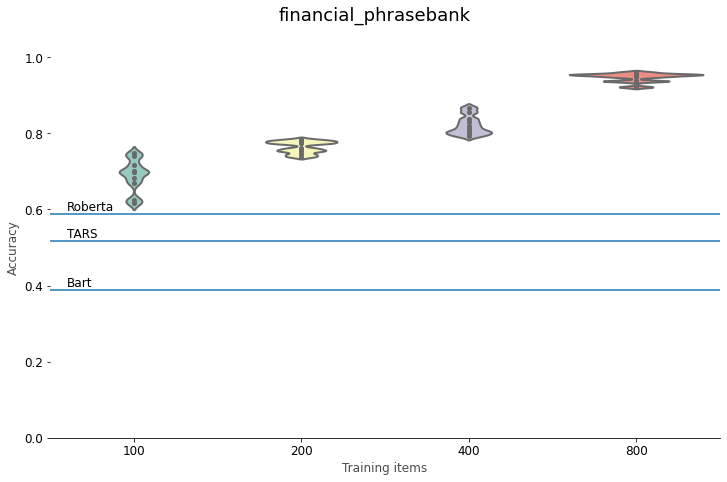
For both polarity tasks, Roberta gives the best results, with 54.0% accuracy for the tweets and 58.8% for the
financial news sentences. TARS and Bart obtain a similar result on the tweets, with 48.2% and 49.0% accuracy, respectively.
On the financial news sentences, TARS is better, with 51.7% against 38.8%.
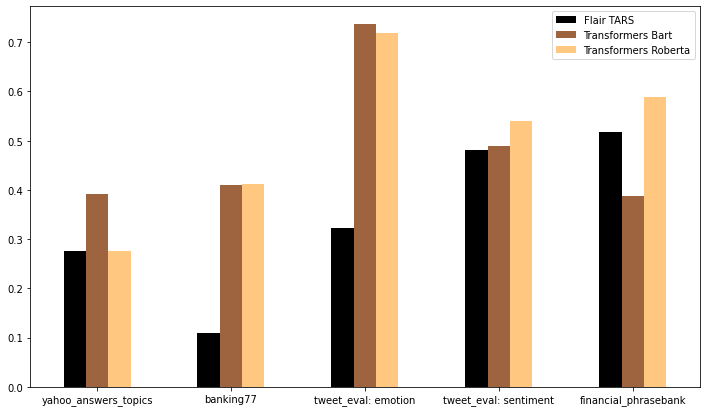
Choosing good class names
In traditional supervised learning, the actual names of the labels do not have any impact on the performance of the
model. You’re free to call your classes whatever you want — positive, politics or aardvark, it makes no
difference at all. In zero-shot text classification, these names suddenly become important. Both the NLI and TARS
classifiers add the label itself to the input of the model, so that the class names have the power to change the predictions.
In general, the more semantic information about the class they contain, and the more similar they are to the type of data that
the model was finetuned on, the better we can expect the classifier to perform.
Let’s take polarity classification as an example. While positive, neutral and negative are the traditional class names for this task,
they may not be optimal for a zero-shot approach. To test this out, we experimented
with two alternative sets of names for the financial news data: good news, neutral news and bad news on the one hand, and happy news,
neutral news and unhappy news on the other. As you can see in the figure below, this has a very positive
effect on the accuracy of the classifiers. Both TARS (62.0%) and Bart (61.9%) now perform better than the original Roberta, although
Bart only does so with the happy/unhappy class names. Roberta itself jumps another 13%, to an accuracy of over 73% with both alternative sets of names.
Zero-shot classifiers may reduce the need for labeling, but they do introduce the necessary task of searching for good class names.
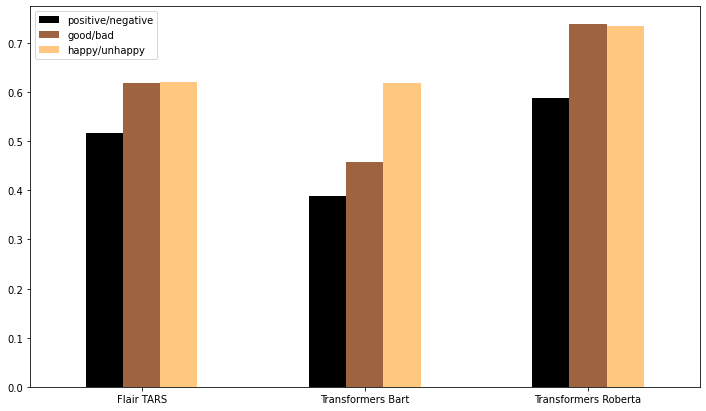
Few-shot learning
As we saw with polarity classification, the TARS classifier tends to suffer from low recall. In tasks with a default class,
such as neutral, this label can serve as a fallback option, but in other cases we need a different solution.
Luckily, Flairs has made it easy
to finetune TARS on a handful of training examples. Let’s see what happens if we give the model one example of what we mean
by each class, and finetune it on this small training set. Because the performance of the final model
will depend on what training instances we pick, we repeat this process ten times and always select random examples from the training corpus.
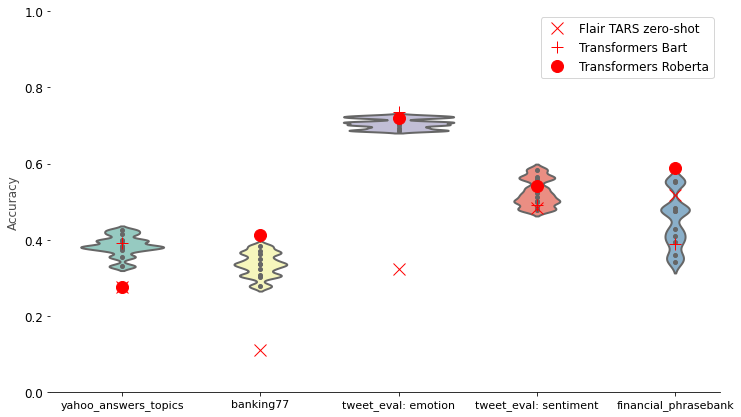
The figure below shows that the TARS classifier benefits greatly from this few-shot learning procedure. The impact is clearest for the three tasks without a default class: TARS’s accuracy jumps significantly, and in two out of three cases it becomes competitive with the best NLI model. Interestingly, this even happens for the emotion dataset, where we’ve used just four examples as our training set. For the polarity tasks, the benefit is less clear, as we already fixed the recall problem by introducing a default class, and only worked with three labeled examples for few-shot learning.
Labeling
To put the performance of the zero-shot models into perspective, it’s useful to ask the question how much
labeling these classifiers help us avoid. To measure this, we finetuned a range of bert-base-uncased models on a random subset
of items from each of our datasets. We experimented with 100, 200, 400 and 800 training items, always
in combination with 100 validation items. As above, we repeated the training process for ten random selections
of training and validation data.
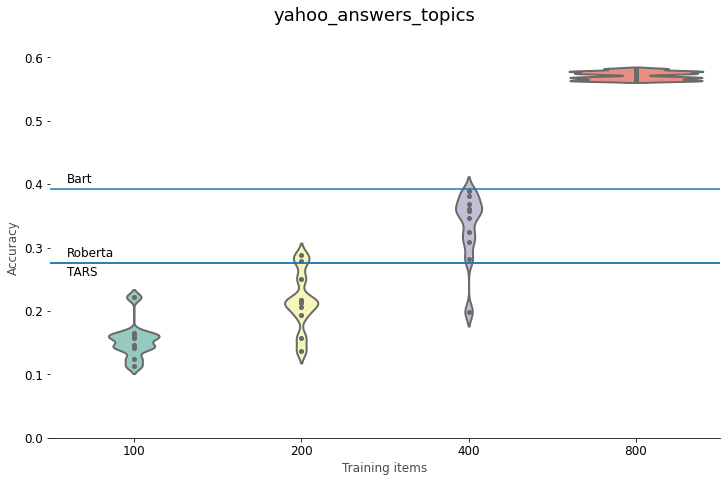
For Yahoo Answers, BERT needs around 400 labeled training texts to beat the Roberta and TARS zero-shot classifiers. 800 labeled examples take it far above the performance of Bart. On our intent classification task, the zero-shot classifiers really stand out. Even with 800 labeled training instances, BERT stays far below the accuracy of the NLI methods. For emotion classification, BERT needs at least 800 labeled examples to outperform the zero-shot models. The same is true for the sentiment polarity classification of tweets, although the difference is less outspoken. Here 800 training examples are always enough to beat the zero-shot approaches, but if you get the right selection, fewer examples can work well, too. Polarity classification of financial news, finally, is right up BERT’s street: here even a small labeled dataset suffices to outperform the zero-shot approaches. Optimizing the class names in the way we described above, makes the best NLI model competitive with a BERT finetuned on 100 training items, but not more than that.
In other words, labeling around 800 training instances usually suffices to beat the zero-shot classifiers,
except in particular cases like the banking77 intent classification task.

Conclusions
Without a doubt, zero-shot learning is an extraordinary application of transfer learning. Zero-shot classifiers predict the class of a text without having seen a single labeled example, and in some cases do so with a higher accuracy than supervised models that have been trained on hundreds of labeled training items. Their success is far from guaranteed — it depends on the particular task and a careful selection of class names — but in the right circumstances, these models can get you a long way towards accurate text classification.
At the same time, the open-source zero-shot classifiers we tested out are no magic solutions, as it’s unlikely they are going to give you optimal performance on a specialized NLP task. For such applications, manually labeling a large number of examples, for example with a tool like Tagalog still gives you the best chance of success. Even in those cases, however, zero-shot classification can prove useful, for example as a way to speed up manual labeling by suggesting potentially relevant labels to the annotators. It’s clear zero-shot and few-shot classification is here to stay, and can be a useful tool in any NLPer’s toolkit.

Yves Peirsman
Yves is the Natural Language Processing expert at NLP Town. He holds an MSc in Speech & Language Processing from the University of Edinburgh, and a PhD in Computational Linguistics from the University of Leuven. After spending some time as a post-doctoral researcher at Stanford University, he traded academia for industry. In 2014 he founded NLP Town to help companies and organizations implement NLP solutions successfully.